Generative AI for the Uninformed
(by the Uninformed)
Presented by
Zackary Lowery
on August 19th, 2025
at Leading EDJE.
Available online at https://presentations.xcjs.com/
Press your space bar or swipe to navigate down and then forward. »
About Me and Why I'm Uninformed
- I'm Zackary Lowery!
-
Currently at
 Leading EDJE
for nearly 10 years!
Leading EDJE
for nearly 10 years!
- Senior Developer
- C#/.NET, frontend web development, and just about anything else.
- Started playing with generative AI in April of 2024.

Topics
Covered
- High Level Concepts
-
Self-hosted Solutions
"Edge" AI Processing
Not Covered
- Low Level Concepts
- Ethical Concerns
- Commercial Services (ChatGPT, etc.)

OpenAI

Generative AI at home:



























...and more!
Hardware Requirements

Requirements by Use Case
| CPU | RAM | VRAM | |
|---|---|---|---|
| LLM | AVX2 Support | 8+ GB | 0-8+ GB |
| Images | * | 16+ GB | 4-12+ GB |
| Video | * | 16+ GB | 12+ GB |
| Audio | * | 16+ GB | 8+ GB |
| 3D Modeling | * | 16+ GB | 16+ GB |
- LLM
- Large Language Model
- AVX2
- Advanced Vector Extensions 2, an instruction set supported by most mid to high end x86_64 processors since 2013. Windows on ARM Insider Build 27744 has added emulation support for this feature.
OS Matters!
- Using a headless Linux install automatically grants you up to an additional 1 GB of VRAM when compared to Windows.

GPU Manufacturer Matters!
- CUDA Acceleration Widely Supported
- ZLUDA?

- CUDA
- Compute Unified Device Architecture, NVIDIA's proprietary API for performing general purpose calculations on GPUs.
- ZLUDA
- A library for adapting CUDA to non-NVIDIA hardware.
Example Hardware Configuration
| Motherboard | Gigabyte B450M DS3H (Micro ATX) |
|---|---|
| CPU | AMD Ryzen 5 1600 Six-Core Processor |
| RAM | 64 GB DDR4 RAM |
| Storage | 2 TB Intel 670p NVME SSD |
| GPU |
|
| Power Supply | 750 Watts |

AI on a Budget
NVIDIA Jetson Orin Nano Super (~$549.99)
| AI Performance | 67 INT8 TOPS |
|---|---|
| GPU | NVIDIA Ampere architecture with 1024 CUDA cores and 32 tensor cores |
| CPU | 6-core Arm® Cortex®-A78AE v8.2 64-bit CPU 1.5MB L2 + 4MB L3 |
| Memory | 8GB 128-bit LPDDR5 102 GB/s |
| Storage | Supports SD card slot and external NVMe |
| Power | 7W-25W |

NVIDIA "Edge AI"
AI on a "Budget"
NVIDIA Project Digits ($3,000+)
| AI Performance | 1 FP4 PetaFLOP |
|---|---|
| GPU | NVIDIA Blackwell (RTX 50 series) GPU |
| CPU | 20-core ARM Grace CPU |
| Memory | 128 GB LPDDR5X |
| Storage | Up to 4 TB 2230 NVME SSD |
| Power | ???W |

Introductory Concepts
Generative AI is Big Statistics
It's statistics all the way down.

Determinism
Generative AI models are deterministic.
Equal inputs = Equal outputs.
What is a Vector?
A vector is an ordered list of numbers.
[10, 96, 72, 31, 98]
Or...
[489.1512, 82.582, 17.124, 857.1723, 15.234]
Vectors have dimension. These examples have 5 dimensions each.
What is a Model?
Models or weights are collections of vectors organized in various architectures alongside other features.
| Name | Description | Extension |
|---|---|---|
| Pickle |
|
.pickle / .pkl |
| Pytorch |
|
.pth |
| Safetensors |
|
.safetensors |
|
GGUF
(GGML Universal File) (Generative Graphical ModeL) |
|
.gguf |
|
ONNX
(Open Neural Network Exchange) |
|
.onnx |
More on ONNX

From ONNX.ai:
ONNX is an open format built to represent machine learning models.
- Strong backing from many technical industry leaders
ONNX and  Microsoft
Microsoft
-
Cross-platform
 ONNX runtime.
ONNX runtime.
- Copilot+ PCs can run machine learning models locally.
-
 Quantized ONNX versions of
Deepseek R1 on Copilot+ hardware.
Quantized ONNX versions of
Deepseek R1 on Copilot+ hardware.
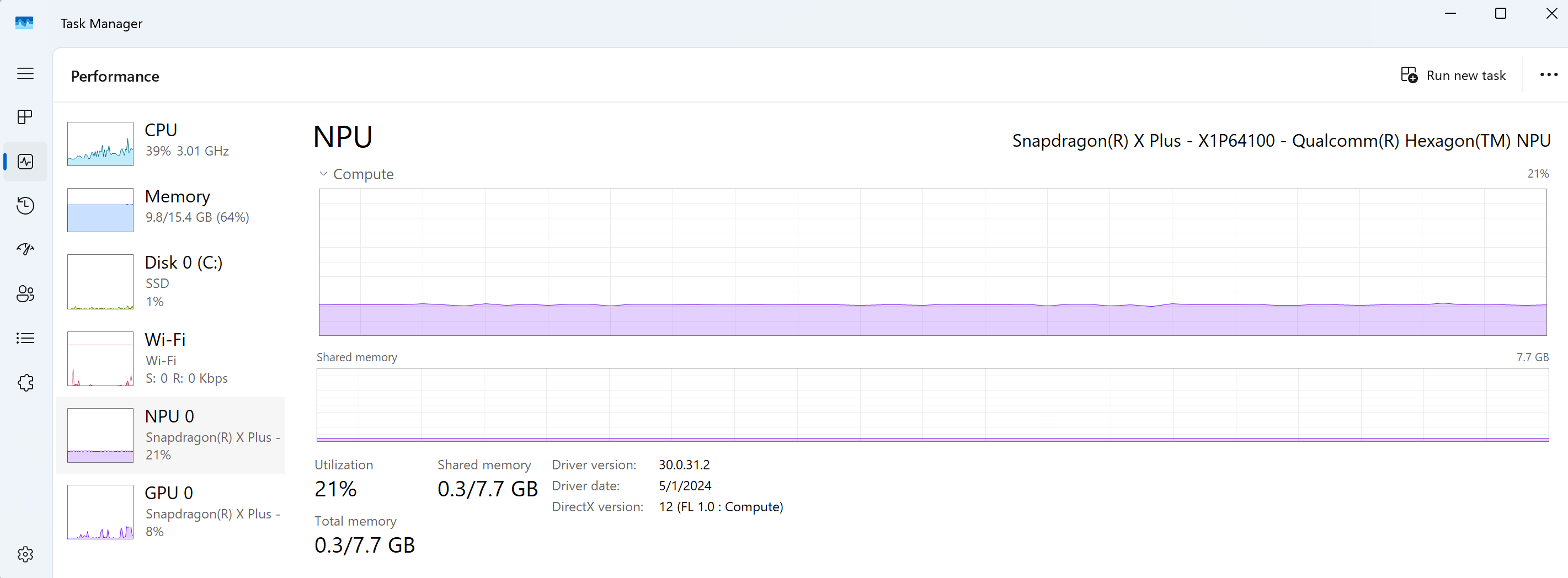
- NPU
- Neural Processing Unit: A special coprocessor optimized to run machine learning models.
Quantization
Lowering the numerical precision of a model to positively impact size and/or performance.
| Name | Parameters | Quantization | Size | (V)RAM |
|---|---|---|---|---|
Fake-8B-q4_0.gguf |
8 Billion | 4-bit int | 4.7 GB | ~5.6 GB |
Fake-8B-q8_0.gguf |
8 Billion | 8-bit int | 8.5 GB | ~10 GB |
Lossless versions of models usually begin with
FP16,
FP32, or
FP64 values before quantization.
Distillation
Using a larger model to train smaller models.
- Distilled models are typically a similar probability distribution of fewer parameters.
| Name | Parameters | Quantization | Size | (V)RAM |
|---|---|---|---|---|
Fake-8B-q8_0.gguf |
8 Billion | 8-bit int | 8.5 GB | ~10 GB |
Fake-70B-q8_0.gguf |
70 Billion | 8-bit int | 75 GB | ~90 GB |
Large Language Models
Prompt
- User-provided text that the LLM responds to.
$ Tell me about the Roman Empire.
Absolutely! The Roman Empire was...
System Prompt
- System-configured prompt to provide instructions or context to subsequent prompts.
- Prefixes or is combined with every user prompt
- Generally not visible or adjustable by the end user.
You are an assistant designed to help the user with
any request or question. Responses should be
accurate and concise. Refuse to answer any request
or question that might be used to harm the user or
another person.
Tokens
- A word, part of a word, or even punctuation.
- Determined by the LLM's tokenizer.
- Each token is assigned and referenced by an integral ID.
 Borrowed from
TeeTracker@Medium
Borrowed from
TeeTracker@Medium
Context
- A summary of the history of the conversation with the LLM or additional tokens provided by other sources.
- Different LLMs can have varying maximum context windows.
[113, 101, 102, 103, 104, 105, 106, 107, 108, 109, 104, 110, 111, 112, 114]
Temperature
How likely an LLM will select the "best" series of tokens in its response.
Cool 0.0 2.0 Warm
0.0
Not an entirely accurate representation as the LLM still selects tokens out of a distribution curve. The curve is just flattened.
Have a great !
| day | 0.8 |
| life | 1.0 |
| dinner | 1.2 |
| holiday | 1.4 |
| paper cut | 1.8 |
| kangaroo | 2.0 |
Mixture of Experts (MoE) Models
A model consisting of multiple networks that specialize in a subset of the total parameters.
Mixtral
Deepseek v3
Llama 4
Reasoning Models
- Chain-of-Thought (CoT) output before prompt response.
- Splits attention mechanism on the prompt into smaller chunks.
User:
What is 1 + 1?
Assistant:
1 is the smallest positive integral value. By
adding 1 to 1, we get the next integer in the
sequence of all integers, which is 2. Therefore,
1 + 1 = 2.
The answer is 2.
Deepseek R1
Phi 4 Reasoning
Magistral
Retrieval Augmented Generation (RAG)
- Convert external data to embeddings.
- Retrieve the embeddings.
- The embeddings are used to augment the user's prompt.
- The LLM generates a response to the prompt.
Embeddings
Embeddings are similar to tokenizing the data, but embeddings also preserve the relationship between tokens.
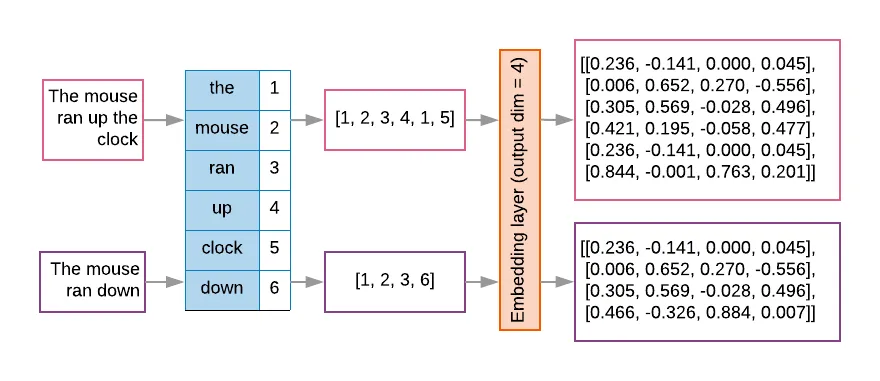
Borrowed from Tokenization vs. Embedding: Understanding the Differences and Their Importance in NLP.
Model Context Protocol (MCP)
- Standardized protocol to contextualize and provide external callable functionality to LLMs.
- Based on JSON-RPC 2.0.

User: Turn on the living room lights.
Assistant: Ok, I turned on the living room lights.
1. MCP Server Lists Functions
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"tools": [
{
"name": "control_lighting",
"title": "Smart Home Control: Lighting",
"description": "Turn lights on or off in a room.",
"inputSchema": {
"type": "object",
"properties": {
"room": {
"type": "string",
"description": "The room to turn the lights on or off in.",
},
"enabled": {
"type": "bool",
"description": "Whether to turn the lights on or off."
}
},
"required": ["room"]
}
}
]
} }
2. MCP Host Calls a Function
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "control_lighting",
"arguments": {
"room": "Living Room",
"enabled": true
}
}
}
3. MCP Server Executes Function and Returns Result
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"room": "Living Room",
"enabled": true
}
}
Notable LLM Projects and Resources
Hugging Face
Online repository for various types of machine learning models.
Llama.cpp
-
Inference engine for the
Meta-developed LLaMA foundational LLM models
- Open-source
- CLI application, server, or standalone library, and more
- Used in nearly all open-source/self-hosted LLM solutions

Ollama
- "Just works" LLM runtime.
- Server manager for queueing requests across multiple models.
- OpenAI compatible API
- Now ships with a desktop application.
ollama serve
- Runs an OpenAI compatible API to facilitate LLM interactions.
- Required to run other Ollama commands.
$ ollama serve
ollama pull
- Download a large language model from Ollama's repository.
-
Model names based on Docker naming convention with tags -
:latestis the default tag.
$ ollama pull llama3:8b
ollama run
- Runs an interactive shell to prompt the LLM.
- Pulls the model if missing.
$ ollama run llama3:8b
Open Web UI
Web frontend for Ollama and other LLM backends
Llamafile
Single-file multi-platform self-contained executable LLM with a CLI or web based frontend
| AMD64 | ARM64 | |
|---|---|---|
| Windows | ✅ | ✅ |
| Linux | ✅ | ✅ |
| Mac OS X | ✅ | ✅ |
| FreeBSD | ✅ | ✅ |
| OpenBSD | ✅ | ✅ |
| NetBSD | ✅ | ✅ |
LM Studio
- Desktop application
- Probably the easiest way to get started with local LLMs.
- Supports starting an OpenAI compatible API.
- Closed source.
Jan
- Desktop application similar to LM Studio.
- Another approachable way to get started with local LLMs.
- Supports starting an OpenAI compatible API.
- Open source.
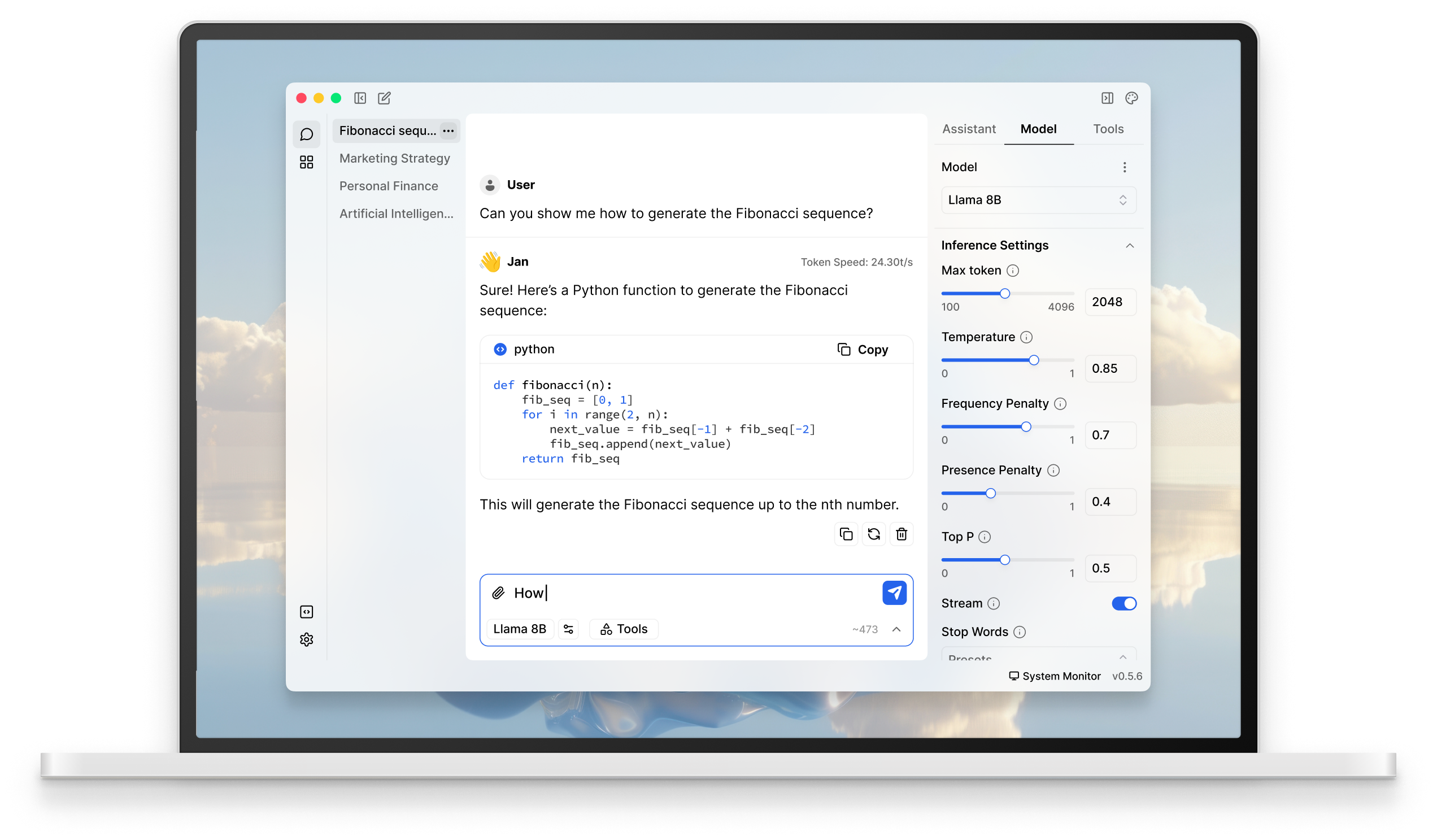
Image Generation

Generative Image Model Convolutions
Borrowed from AI, But Simple.
Latent Space
A low-dimensional or set of low-dimensional vectors representing an image or image canvas
[
0, 0, 0,
0, 0, 0,
0, 0, 0
]
UNet Model
- The main generation model, typically a CNN (convolutional neural network).
- Predicts an image by iteratively removing noise in the latent image.
- U-like shape of the image encoding and decoding process.
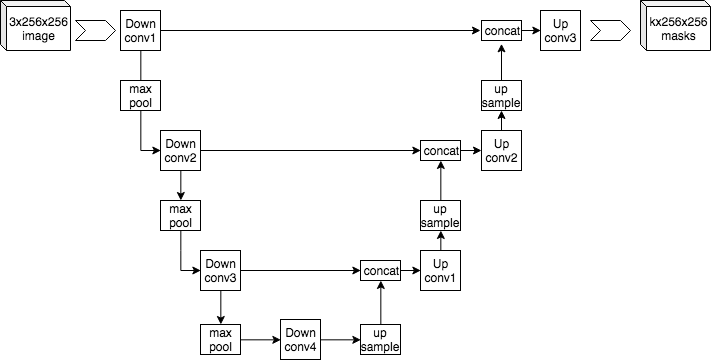
The UNet architecture. Don't ask me how it works yet. Borrowed from Wikipedia's U-Net article.
Prompt
A description of an image.
A photo of an astronaut riding a horse.

Text Encoder
Tokenizes the prompt into a vector.
Borrowed from
TeeTracker@Medium
CLIP Dictionary
Contrastive Language-Image Pre-training
See also: Multimodal Embeddings - relates vectors from multiple parameter types.
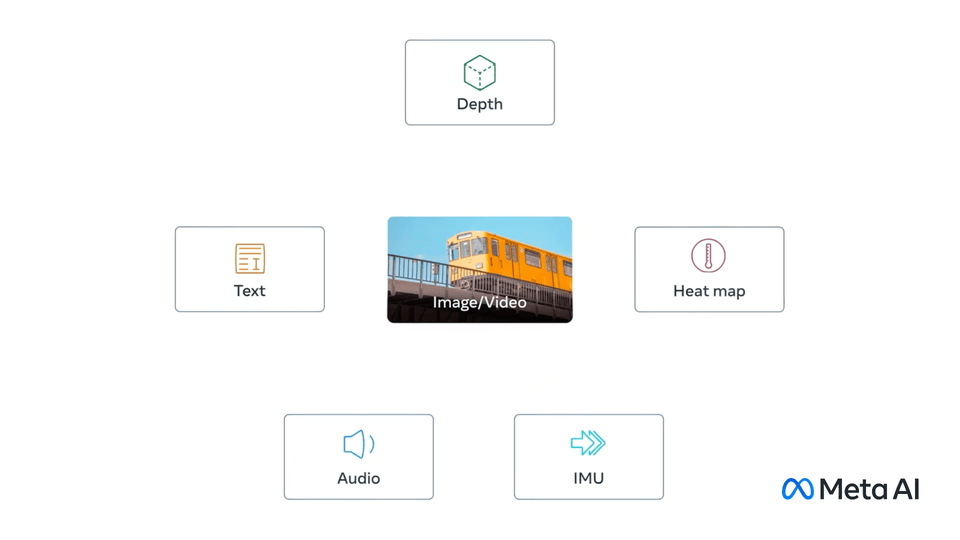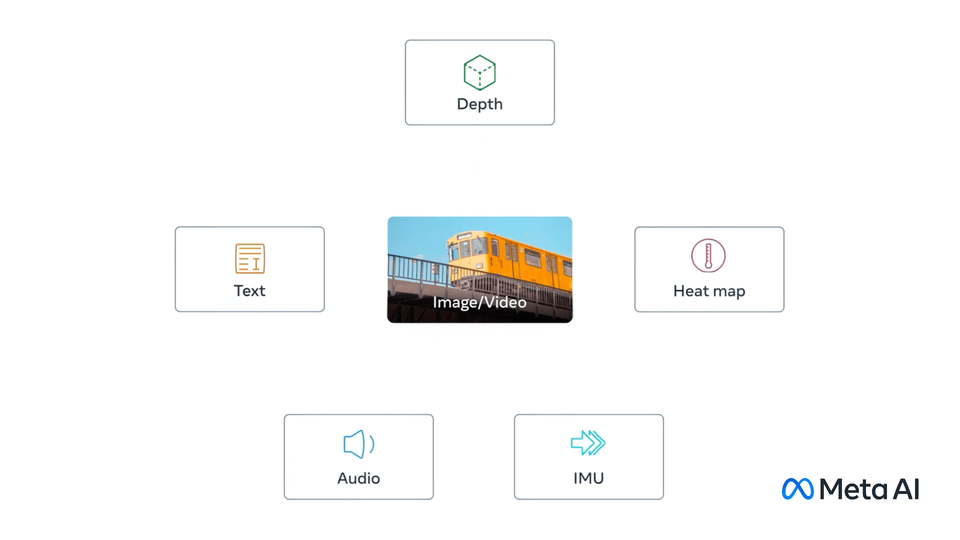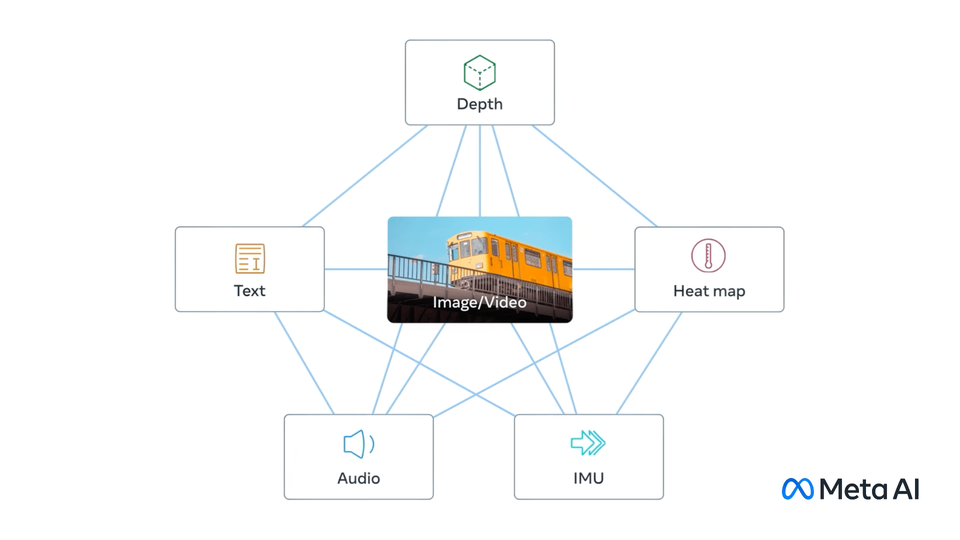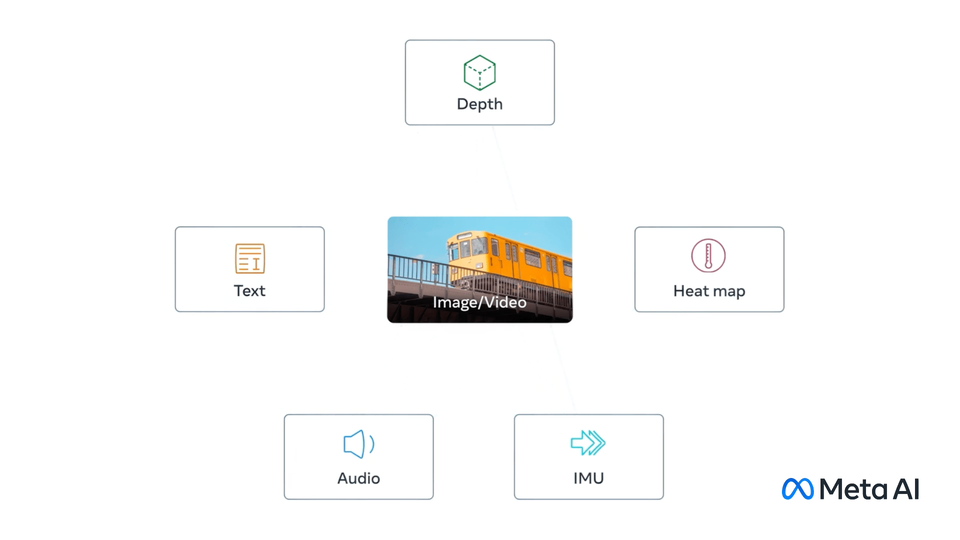 Borrowed from Meta's ImageBind.
Borrowed from Meta's ImageBind.
KSampler
- Add visual noise based on seed and noise strength.
- Load UNet model.
- Iterate in steps based on positive and negative guidance (prompts).

Seed
An integer used to generate the starting noise pattern.
657835674309455Steps

An image at 1, 5, 10, 15, and 20 steps.
Sampler
Samplers control the denoising process.

euler

heun

dpmpp_sde

dpmpp_2m_sde
Scheduler
Schedulers control the level of noise at each step.
simple

karras

normal

sgm_uniform
Guidance Scale
The priority level of the prompt.

3.5
7.0

14.0

28.0
Variational Auto Encoder (VAE)
Converts the latent image to a pixel bitmap.
[
-3.609193, -6.2027211, -3.2266970,
9.5763211, 1.2311611, -2.2856392,
-5.266179, 2.9949563, -5.5448007,
etc...
]
→
Stable Diffusion
Long-time open-source/open-weight image generation models from Stability AI.
| Version | Resolution | Release Date |
|---|---|---|
| 1.x | 512x512 | 2022-08-22 |
| 2.x | 1024x1024 | 2022-11-23 |
| XL | * | 2023-07-18 |
| 3.0 | 1024x1024 - 2048x2048 | 2024-06-12 |
| 3.5 | * | 2024-10-22/29 |
Flux
Open source inference engine and open/closed weight models from Black Forest Labs that challenged Stability AI's Stable Diffusion 3.0 release.
| Version | Resolution | Release Date |
|---|---|---|
| Flux.1 Pro/Dev/Schnell | 1024x1024 | 2024-08-01 |
| Flux.1 Kontext | * | 2025-05-29 |
| Flux.1 Krea | * | 2025-07-31 |
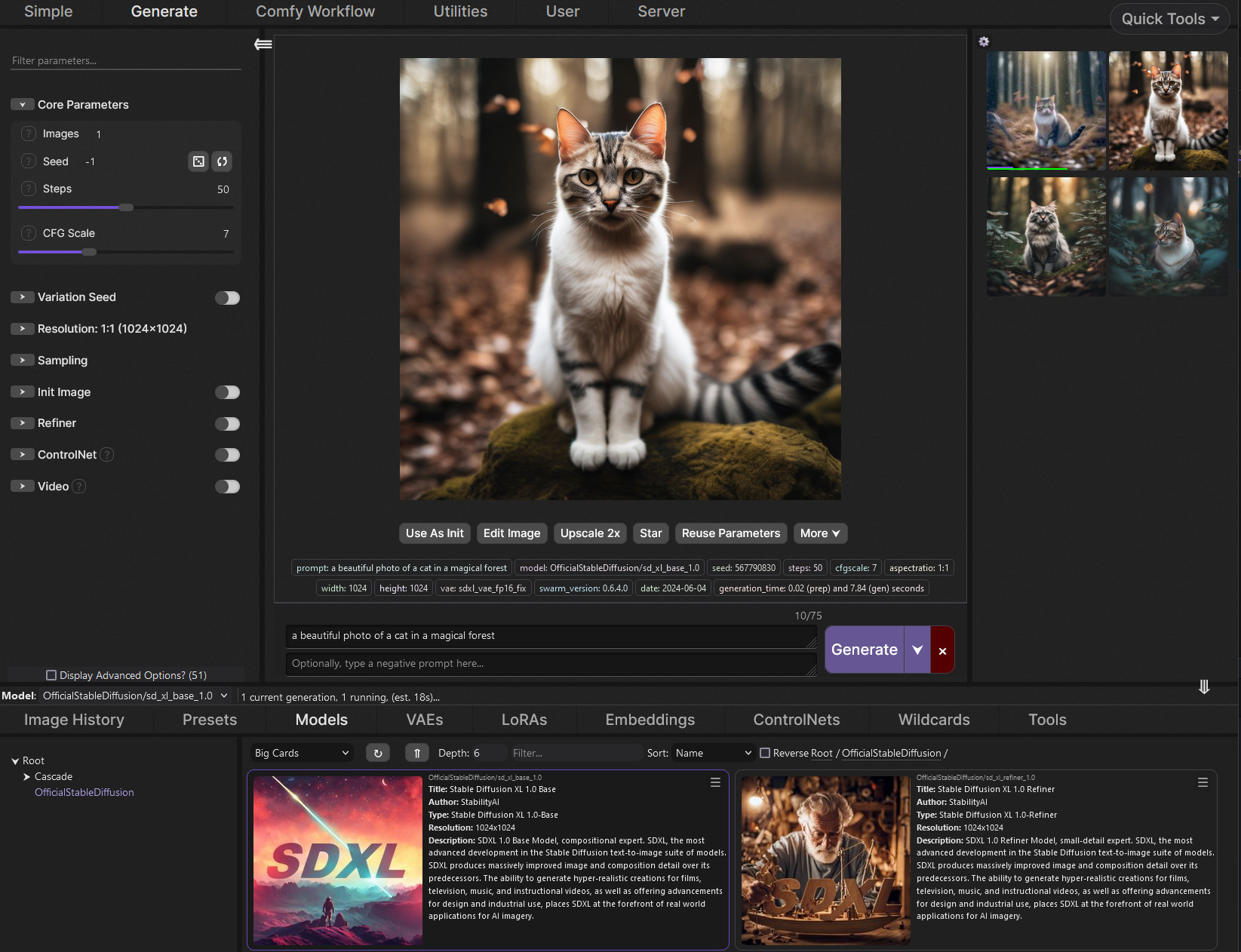
Notable Image Generation Projects and Resources

SD.Next
A great beginner-friendly image generation web application with support for the latest models.
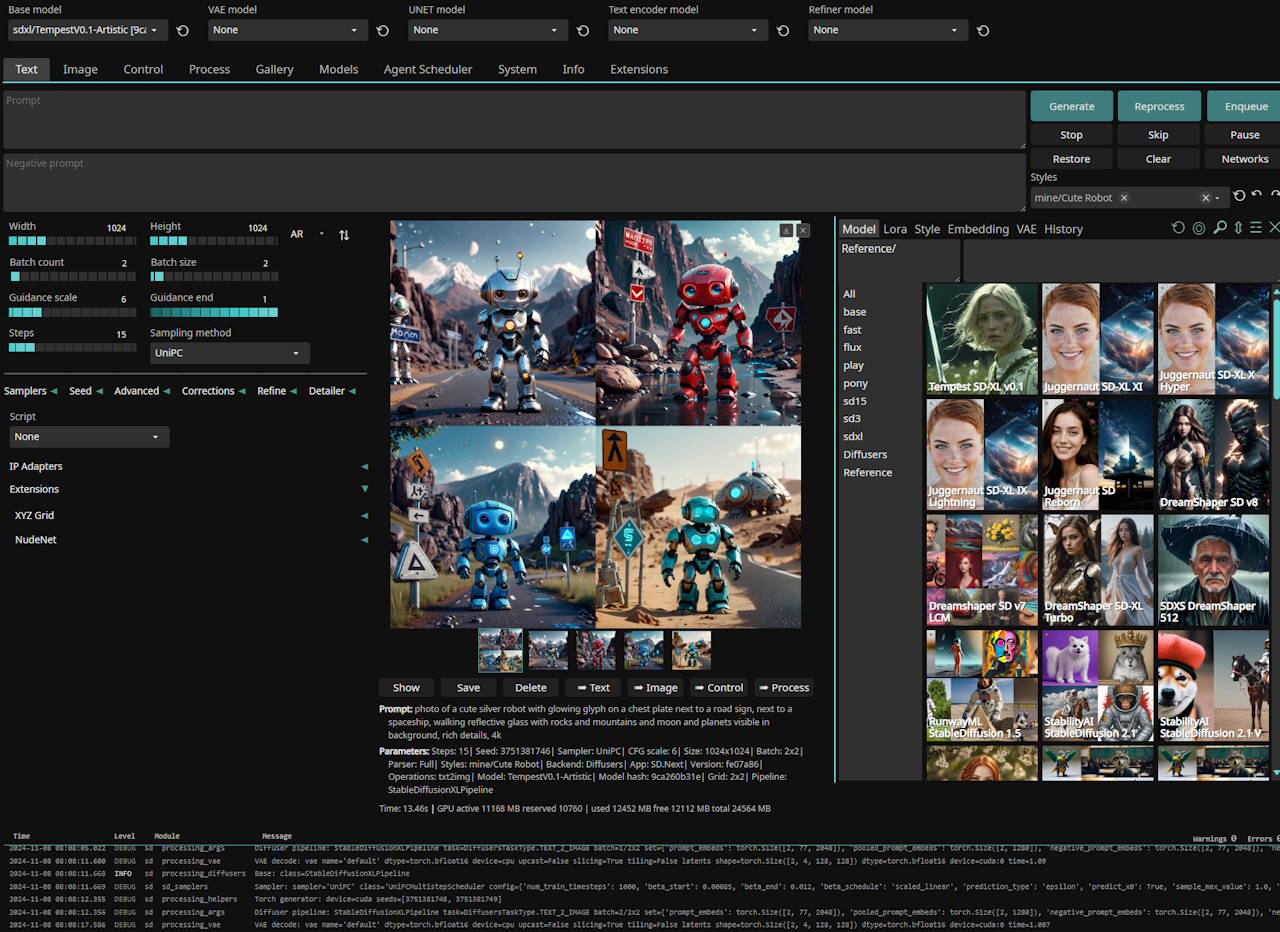
ComfyUI
Advanced industry-standard node-based generative AI toolkit.
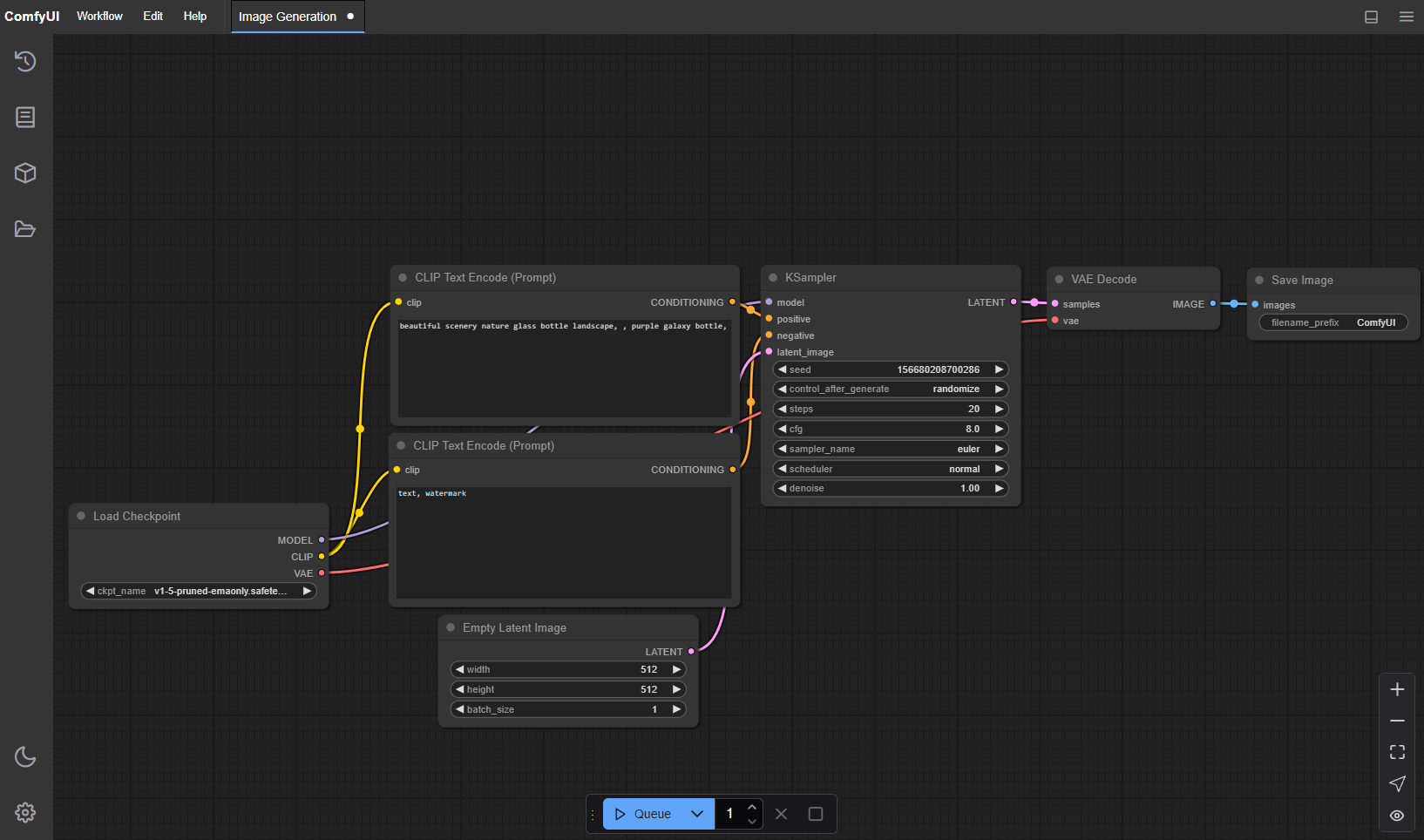
SwarmUI
Assistive wrapper around ComfyUI.
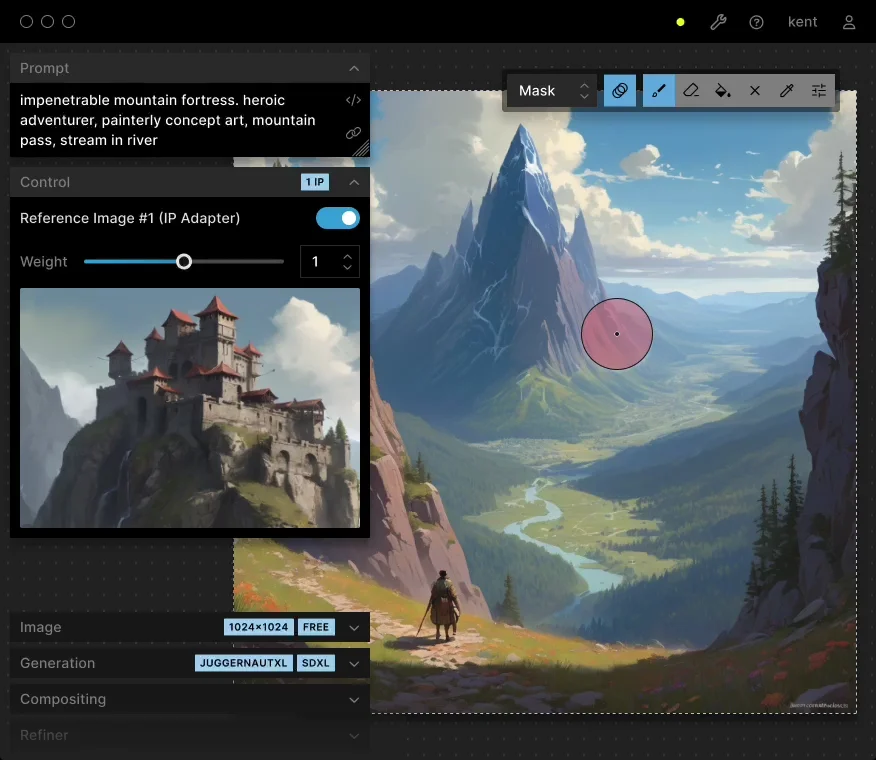
Invoke
- Canvas
- Textbox
- Selection Tool
Paint with AI-driven inpainting.
Video Generation






"Spacetime Latent Patches"
Adding dimensionality around space and time to latent images helps produce video.

Borrowed from OpenAI's Video Generation Models as World Simulators.
Mochi
Early open source video model from Genmo.
 Wan 2.1
Wan 2.1
More recent and more capable open source video model from Alibaba.
Wan 2.2 was announced August 1st.
Audio Generation
Meta Audiocraft
AudioGen
Whistling with wind blowing
MusicGen
Pop dance track with catchy melodies,
tropical percussion,
and upbeat rhythms,
perfect for the beach
 ACE-Step
ACE-Step
Open source/weight foundational music model with official support for ComfyUI.
electronic, rock, pop
(Verse 1)
🎵🎵🎵
It's not just a dream, it's the start of a way,
Building the future where music will play.
A model that listens, a model that grows,
ACE-Step is the rhythm the new world knows.
(Pre-Chorus)
No more limits, no more lines,
A thousand songs in a million minds.
We light the spark, we raise the sound,
A new foundation breaking ground.
(Chorus)
ACE-Step, we take the leap,
Into a world where the music speaks.
Fast and free, we shape the skies,
Creating songs that never die.
ACE-Step — the beat goes on,
Foundation strong, a brand-new dawn.
🎵🎵🎵
(Verse 2)
🎵
Not just end-to-end, but a canvas to paint,
A million colors, no need to wait.
For every artist, for every sound,
ACE-Step lays the sacred ground.
(Pre-Chorus)
🎵
No more limits, no more lines,
A thousand songs in a million minds.
We light the spark, we raise the sound,
A new foundation breaking ground.
(Chorus)
🎵
ACE-Step, we take the leap,
Into a world where the music speaks.
Fast and free, we shape the skies,
Creating songs that never die.
ACE-Step — the beat goes on,
Foundation strong, a brand-new dawn.
(Bridge)
🎵
From every beat to every rhyme,
We build the tools for endless time.
A step, a song, a dream to keep,
ACE is the promise we will leap.
(Final Chorus)
🎵
ACE-Step, we take the leap,
Into a world where the music speaks.
Fast and free, we shape the skies,
Creating songs that never die.
ACE-Step — the beat goes on,
Foundation strong, a brand-new dawn.
ACE-Step — the future's song.
3D Model Generation
Hunyuan3D 2.0
An open source/weight 3D model generation model by Tencent.
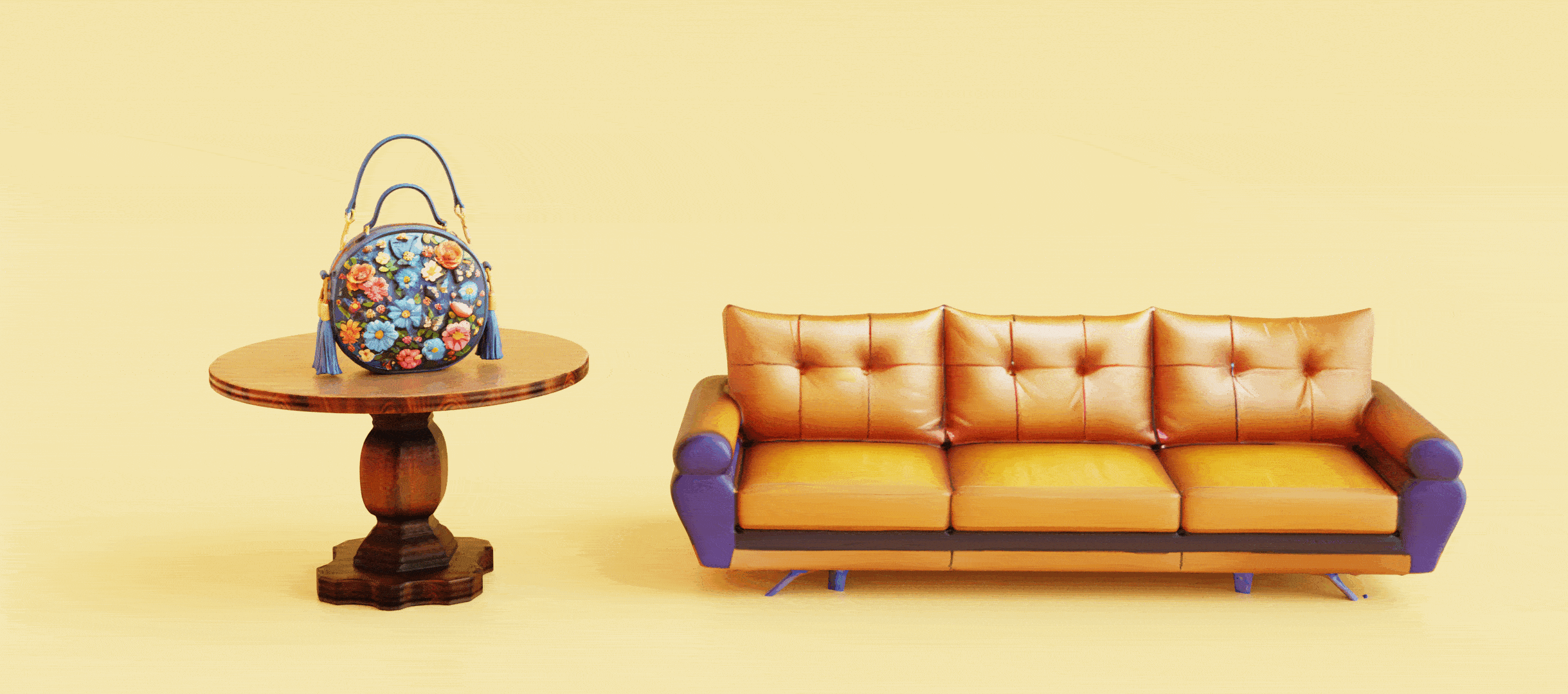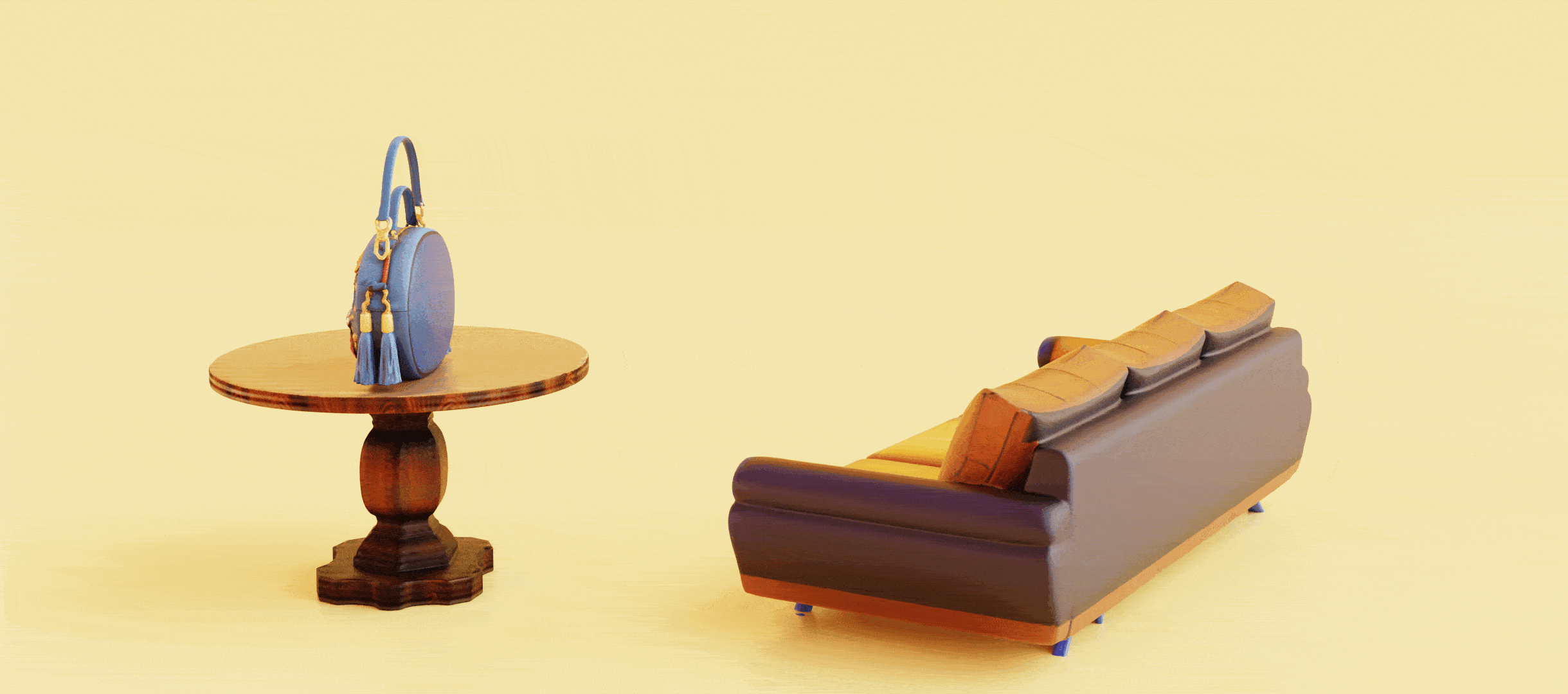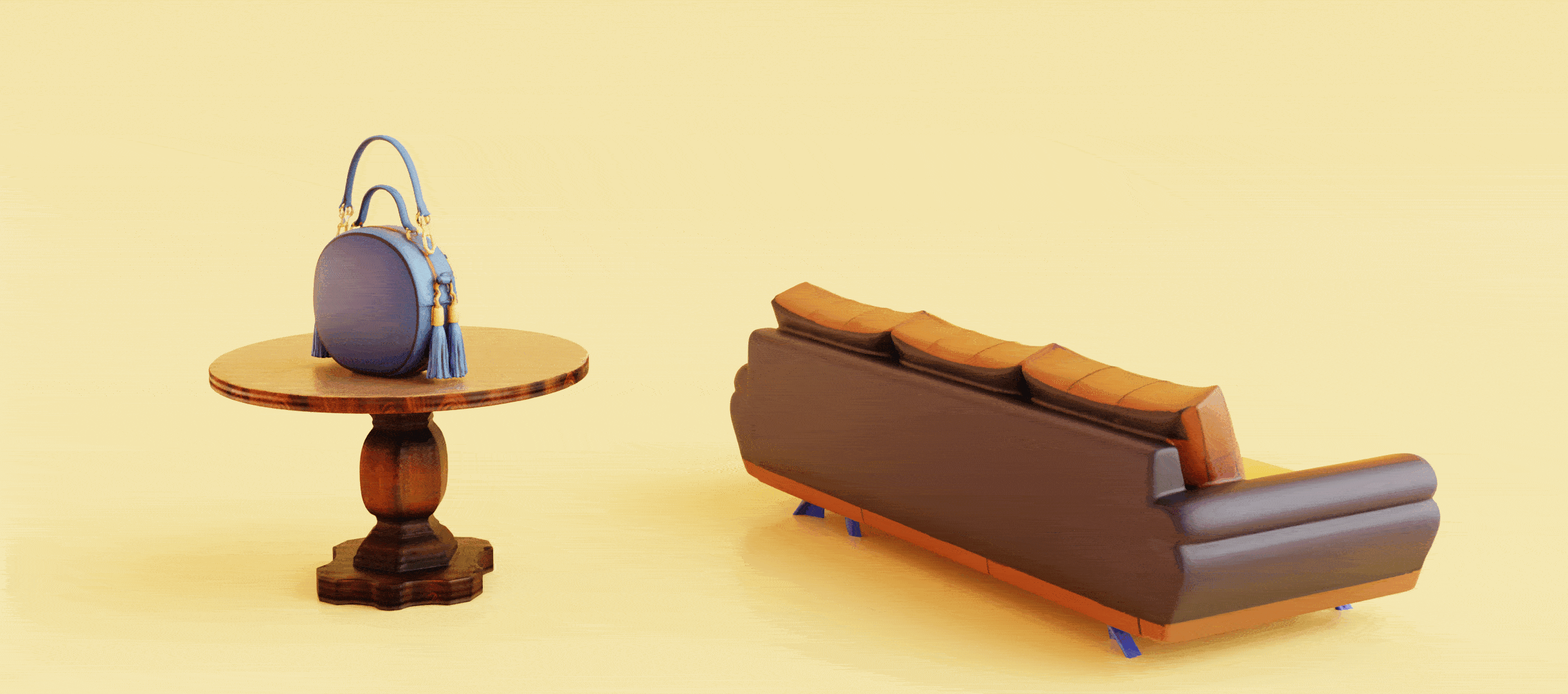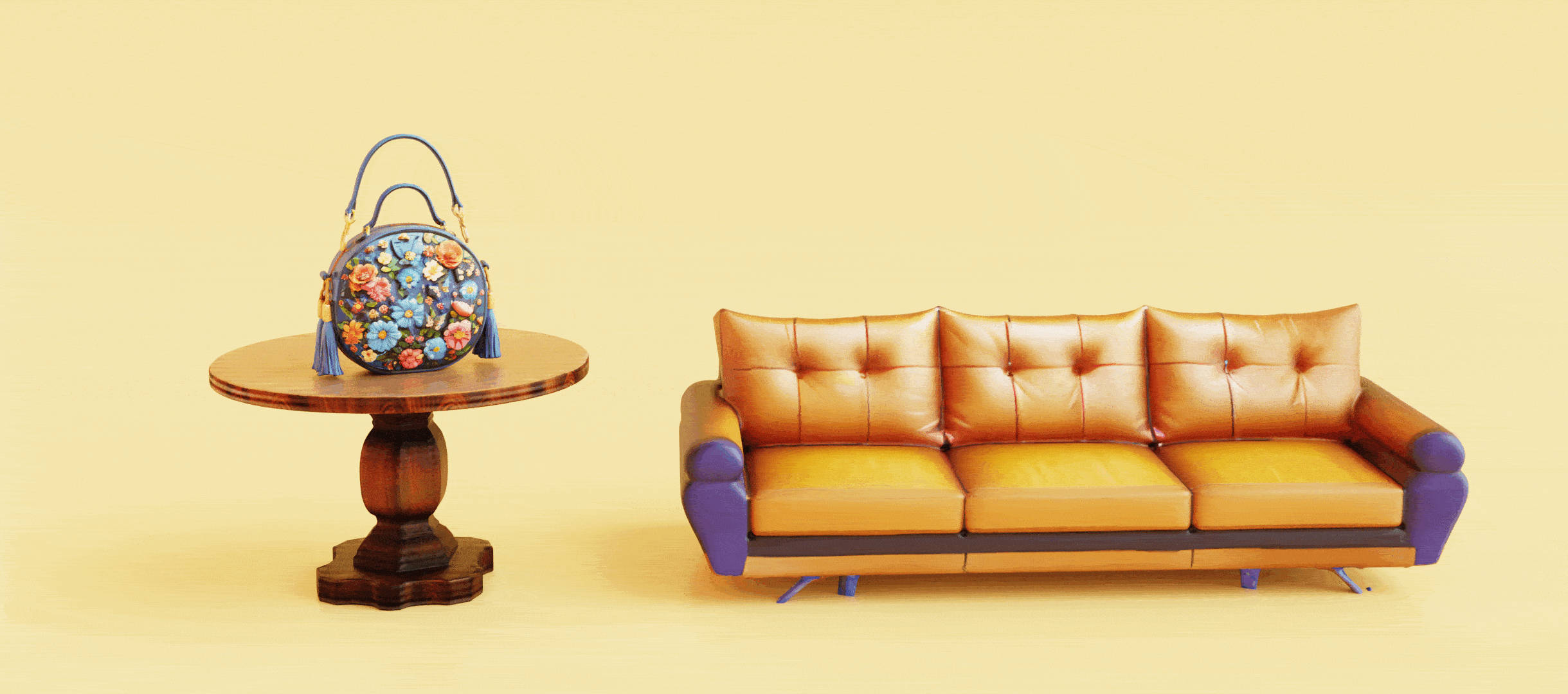
End
Insert discussion and discourse here.
Return to the rest of the presentations.